谷歌TPU调研
张量处理器(Tensor Processing Unit,TPU)是谷歌针对深度学习推出的一款加速器。早在2006年谷歌的工程师们就讨论过在数据中心内部署类似的器件,但当时适用于其上的应用很少,部署的成本相对较高,因此搁置了几年。但2013年由于AlexNet的推广,谷歌预测接下来几年语音搜索会广泛应用,如果用户每天语音搜索的时间达到三分钟,谷歌数据中心的规模需要翻倍才能满足这种需求。因此谷歌立刻启动了一个使用ASIC进行加速的项目,并期望性能可以达到GPU的十倍以上。15个月后,TPU诞生。
第一代
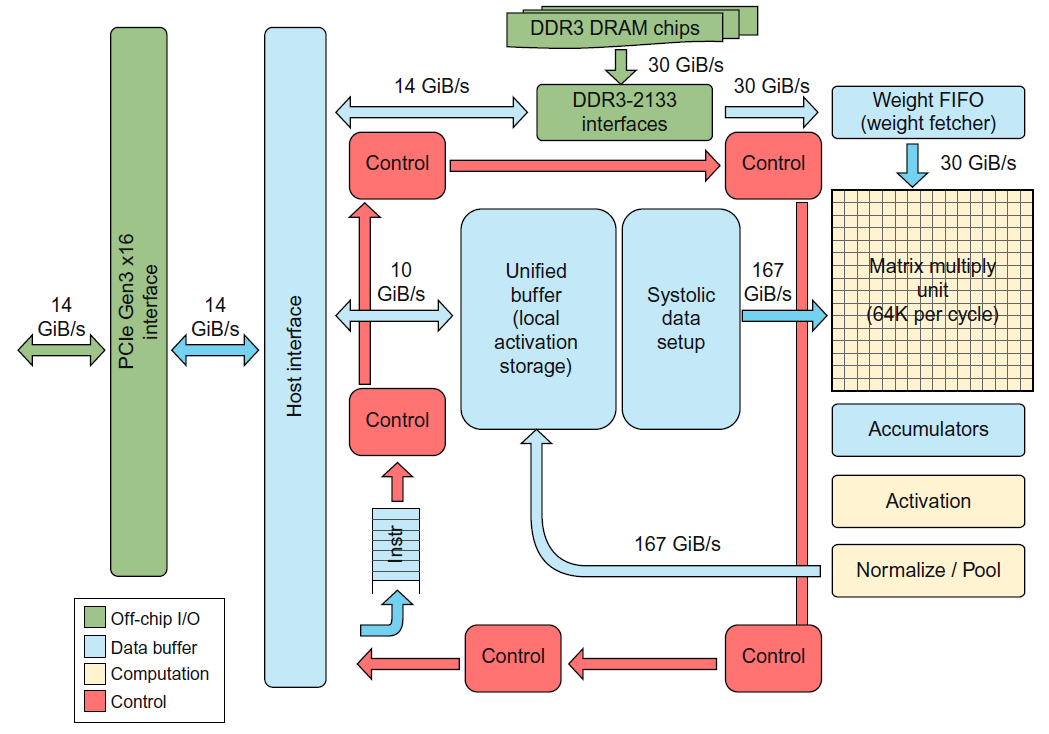
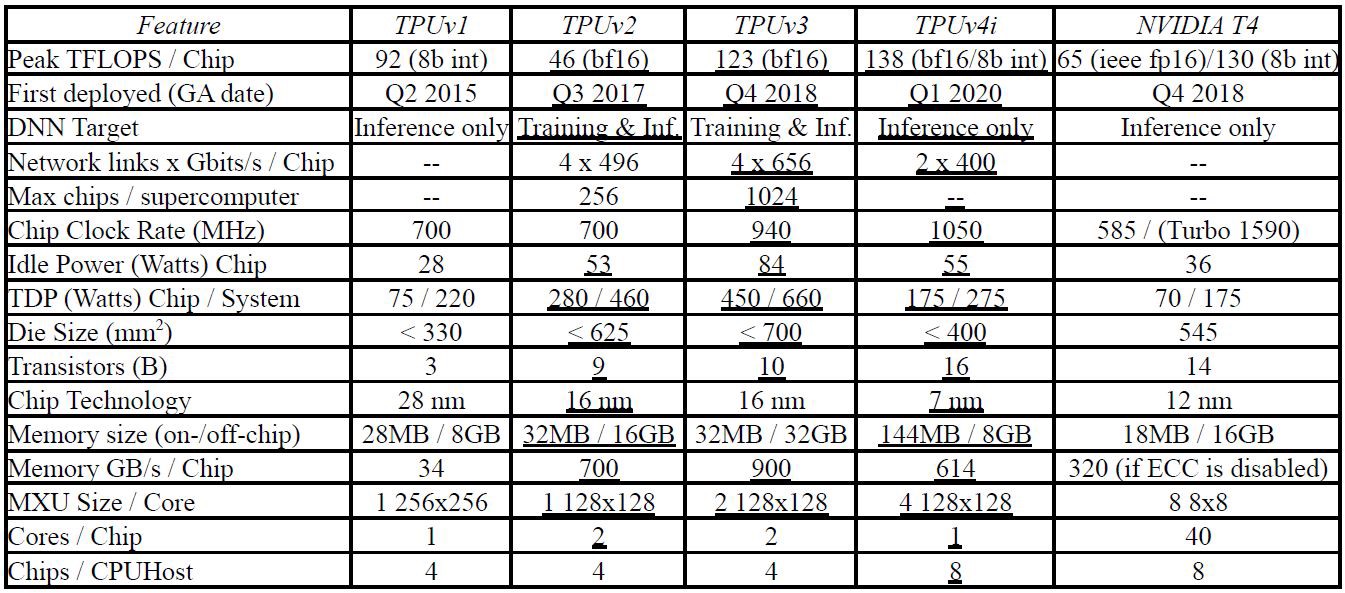
TPUv1在2015年第二季度部署,仅支持推理过程,也就是说只能执行一个成熟的DNN模型。其核心部件是一个矩阵乘法阵列,其中有256x256个ALU,每个ALU是一个8位乘加器,组成systolic架构进行矩阵乘运算,每个时钟周期可以进行25万次运算。
第一代TPU不是冯诺依曼架构,其中没有取指环节,而是主机将指令送给TPU上的指令buffer中,其更像是一个浮点处理器而不是GPU。指令类似CISC,每条指令的执行时间(CPI)为10-20个时钟周期。TPU内部通过256位宽线路互连。下图中浅黄色的部件为计算部件,分为矩阵乘和激活两部分。两个计算部件之间有两个167GB/s的数据buffer,而由于推理过程中参数不需要更新,因此右上角的Weight FIFO相比于数据buffer的带宽低很多,只有30GB/s。
第二代
TPUv1没有面向用户开放,仅仅被谷歌公司自己用作搜索加速。然而深度学习过程中训练过程占用了大部分时间,出于对训练加速的需求,2017年谷歌又部署了TPUv2。训练过程相对于推理过程更加复杂,对TPU的要求更高,表现在以下方面:
- 计算更复杂,推理过程一般包含109次浮点运算操作,而谷歌的训练过程中包含了1019~1022次浮点操作,相差十个数量级以上;
- 需要更大内存已保存反向传播过程中产生的大量临时数据;
- 需要更宽的操作数以提高精度,TPUv1采用的8位int类型不能满足需求;
- 相比于推理过程可以让各个部分独立执行,训练过程需要多个芯片之间进行频繁的参数交互,通信要求更高。
架构
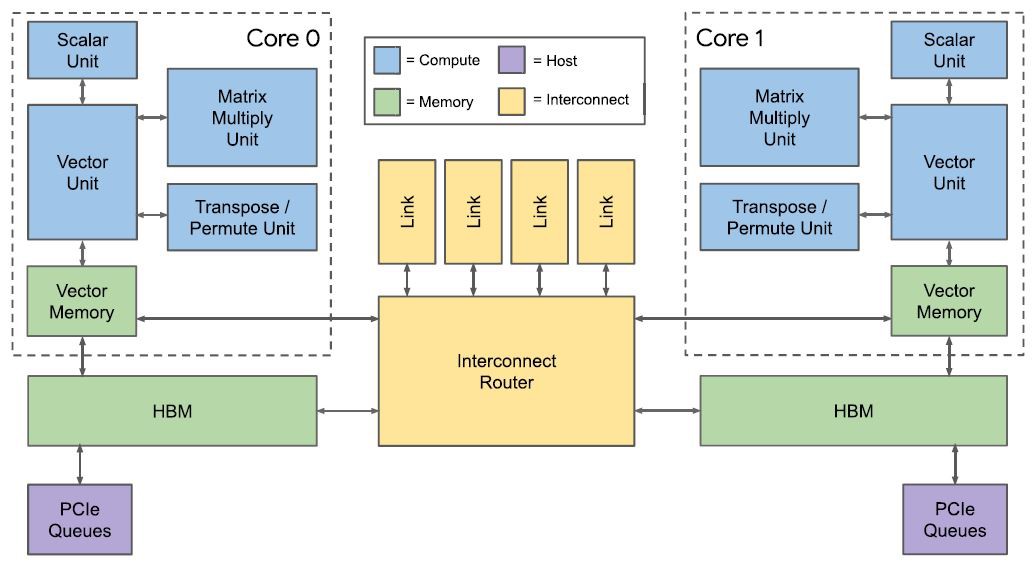
由于计算模式的改变,TPUv1的数据buffer->矩阵乘模块->数据buffer->激活函数框架不适用于训练过程。因此,两个数据buffer合并为一个通用存储器以提高灵活性;加入可编程向量单元(Vector Unit),新架构可以看作以向量单元为中心,矩阵乘单元作为向量单元的协处理器;为了支持可扩展性,存储单元与一套自定义的片间互连模块(Interchip Interconnect, ICI)相连。此外,第二代TPU采用了bf16数据类型,以牺牲精度的代价达到与fp32同样的取值范围。
计算单元
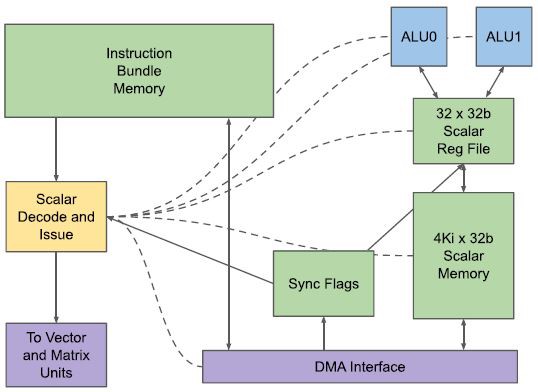
TPUv2加入了取值功能,所用的一个VLIW语句为322位,包含两个标量操作、四个向量操作(包含两个load/store操作)、两个矩阵操作(push和pop)、一个杂项操作和六个立即数。
标量计算单元(Scalar Computation Unit, SCU)负责从指令存储器中取指以及执行标量操作,然后将指令传递给VCU。
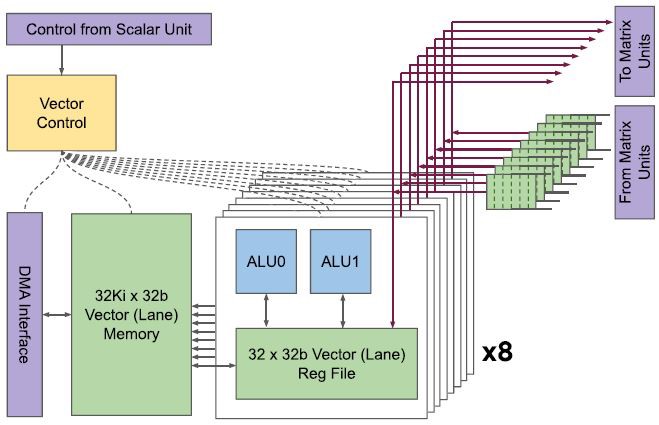
SCU完成译码之后,会将指令传递给向量计算单元(Vector Computation Unit, VCU)。一个VCU有128个lane,一个lane有8个sublane。每个sublane包含一个32位双发射ALU,因此每个VCU在每个时钟周期内总共可以处理八组128位宽的向量。
VCU执行VLIW中的向量操作,以及通过矩阵操作中push和pop的方式与128x128矩阵计算单元进行交互。
存储器系统
互连
一个芯片中有四个片间链路(ICI)和两个片内链路。片上链路与一个片上路由器连接,而ICI将多个TPU组成了一个2D torus网络,以契合机器学习的通信模型——深度学习的训练过程中大多数流量是参数更新而产生的all-reduce。每个ICI带宽为500Gbps。通过这套网络,一个TPU系统最多支持256个TPU芯片协同工作。
从而得以实现一个256节点的分布式训练集群,这个集群中的TPU芯片组成2D-torus拓扑,以契合训练过程中产生的all-reduce流量。
一个TPU板包含四个TPU芯片,每个TPU芯片包含两个核。
第三代
TPUv3在2018年第四季度部署,在架构上并没有做过多调整,只是性能参数上有所提升,例如提高了矩阵乘单元的密度、提高时钟频率等等。
第四代
TODO