论文笔记:A RISC-V In-Network Accelerator for Flexible High-Performance Low-Power Packet Processing
2017年苏黎世联邦理工学院的Hoefler团队提出了一种基于RDMA的在网计算的编程模型 sPIN,2021年此团队使用verilog实现了与此编程模型相对接的硬件 PsPIN,这项工作目前尚未发表,仍然收录在Arxiv中。
背景
在网计算(In-Network Computing)有四个方面的优势:减轻CPU负担、降低延迟、提高吞吐量以及减少资源利用。
目前在网计算的工作可以由四个维度进行衡量:位置、可编程性、计算粒度和可用性。位置可以分为计算逻辑在网络设备的数据路径上、在网络设备但不在数据路径上以及在主机上。在可编程性方面,有的工作支持的自定义操作包括读取数据包头和负载、访问网卡和主机的内存以及发起新的网络请求,而有的工作仅支持预定义的有限操作。这些操作的粒度分为整条消息或单个数据包。可用性是指注册自定义操作是否需要更高级别的权限、服务中断等。下图为几种在网计算工作在这四个维度上的总结。

sPIN
sPIN将RDMA语义扩展,允许用户自定义简单的包处理任务,这些任务称为handler。handler在主机上交叉编译。对每一种消息需要分别对包头、负载和包尾定义三种handler,消息描述符中含有需要进行的handler的信息。
// sPIN介绍待细化
PsPIN硬件架构
PsPIN基于PULP使用RISC-V作为在网计算的处理单元。下图为PsPIN的硬件架构图。每一个集群(cluster)中包含多个HPU,一个HPU是一个32位单发射顺序RISC-V核。图中共有四个集群,每一个集群中有8个HPU。L2 handler memory中存储handler需要的数据,program memory中存储handler程序,packet buffer存储需要处理的数据包。前两者都准备好后,主机向网卡配置运行上下文,其中包含数据包计算条件和内存信息。
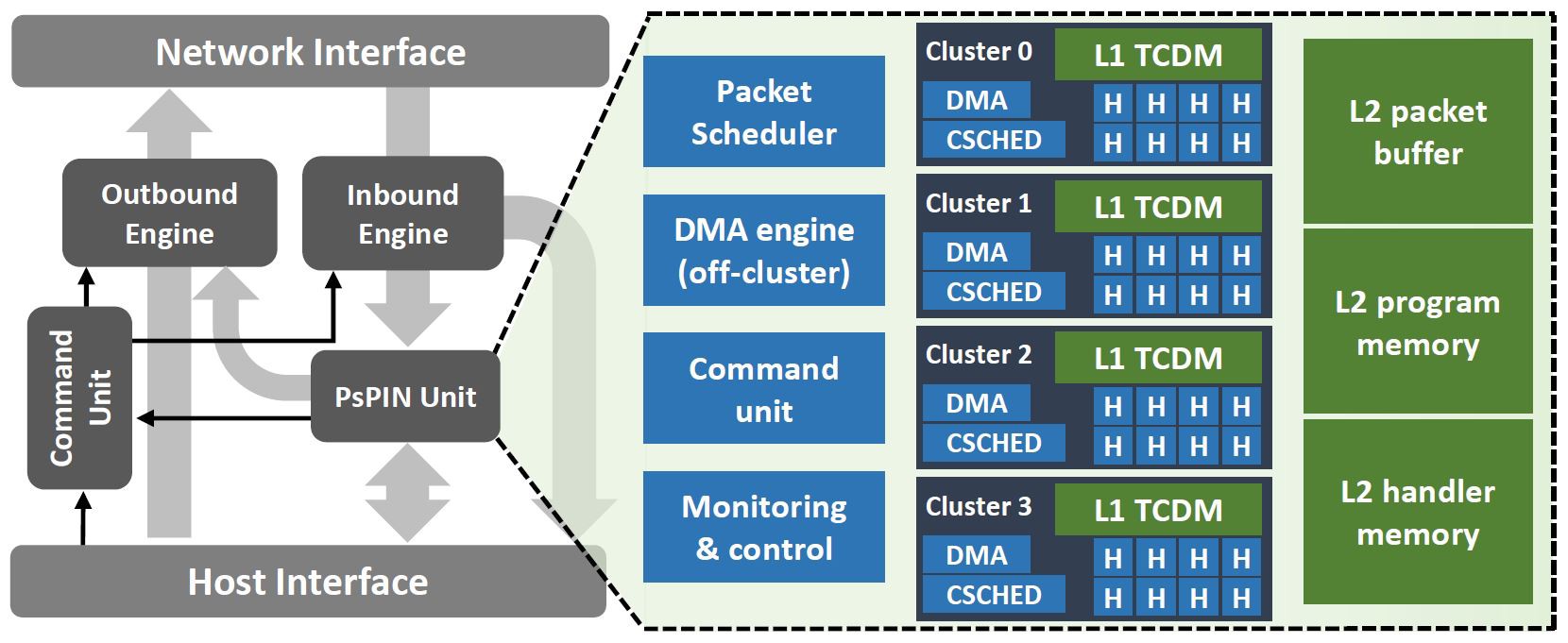
PsPIN Unit
inbound engine处理网络接收到的数据包,对数据包进行判断,如果满足计算条件则转存在PsPIN Unit中的packet buffer中,并向包调度器(Packet Scheduler)发送一个包含数据包指针以及运行上下文的处理请求(Handler Execution Request, HER),之后由包调度器选择特定的集群进行计算。为了尽量避免同一条消息的数据包调度到不同集群从而引发跨集群访存,每一条消息指定一个首位集群(home cluster),包调度器优先将此消息调度至首位集群中,如果首位集群的L1没有足够的空间容纳数据包,则会调度至负载最少的集群。
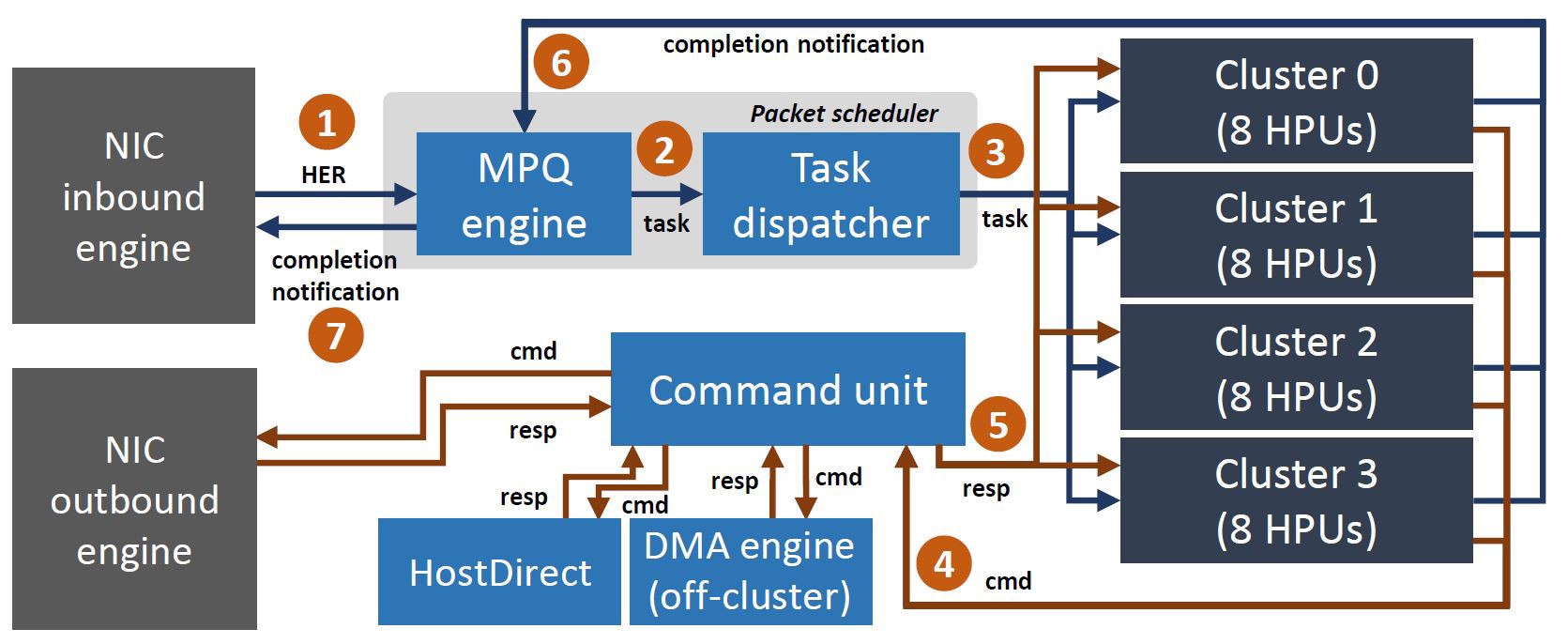
RISC-V集群
包调度器选择一个特定的集群后,此集群通过DMA将数据包从L2读取到L1中,从而能够单周期访存。集群内调度由硬件完成,因为软件调度开销过大。
HPU执行分为四部分:1、从HPU driver中获取handler函数指针;2、准备数据包指针;3、调用handler函数;4、向HPU driver发送完成门铃。HPU在这四个步骤之间循环。当一个handler执行完毕之后,由于有可能handler会向网络端或者主机发送消息,HPU driver等待这一部分任务结束之后向MPQ Engine发送一个完成信号。
在HPU集群内部有三个需要处理的问题:非法访存、数据包乱序和非线速处理。
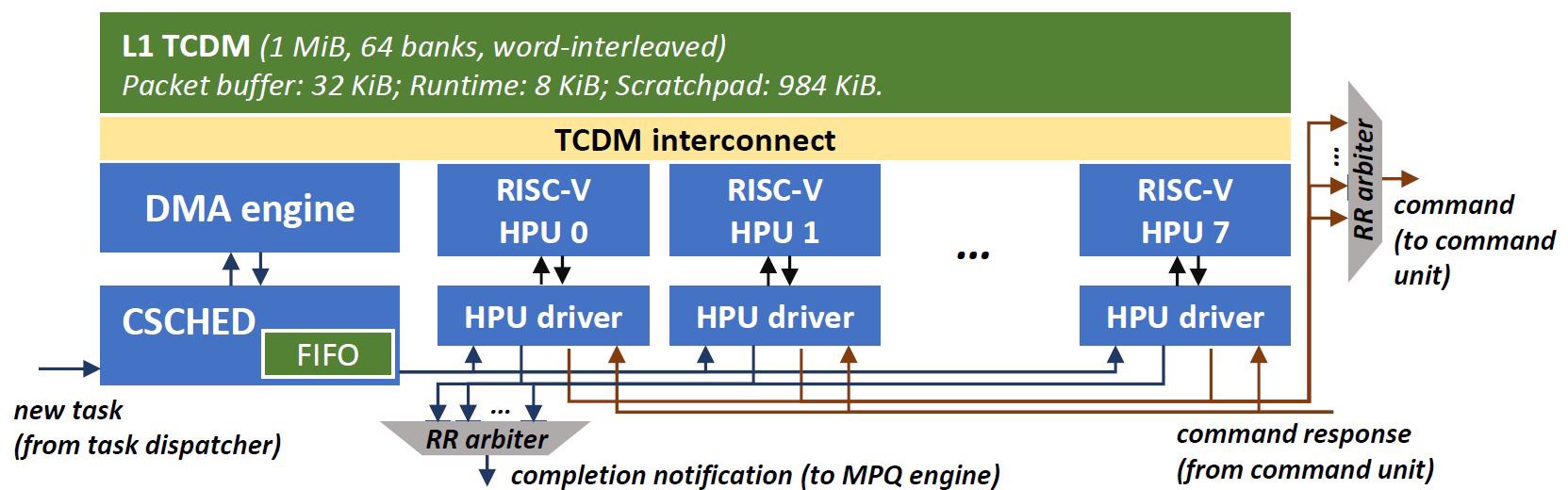
L2 packet buffer是影响数据通路性能的最大瓶颈,因此要保证这一部分内存的高带宽。
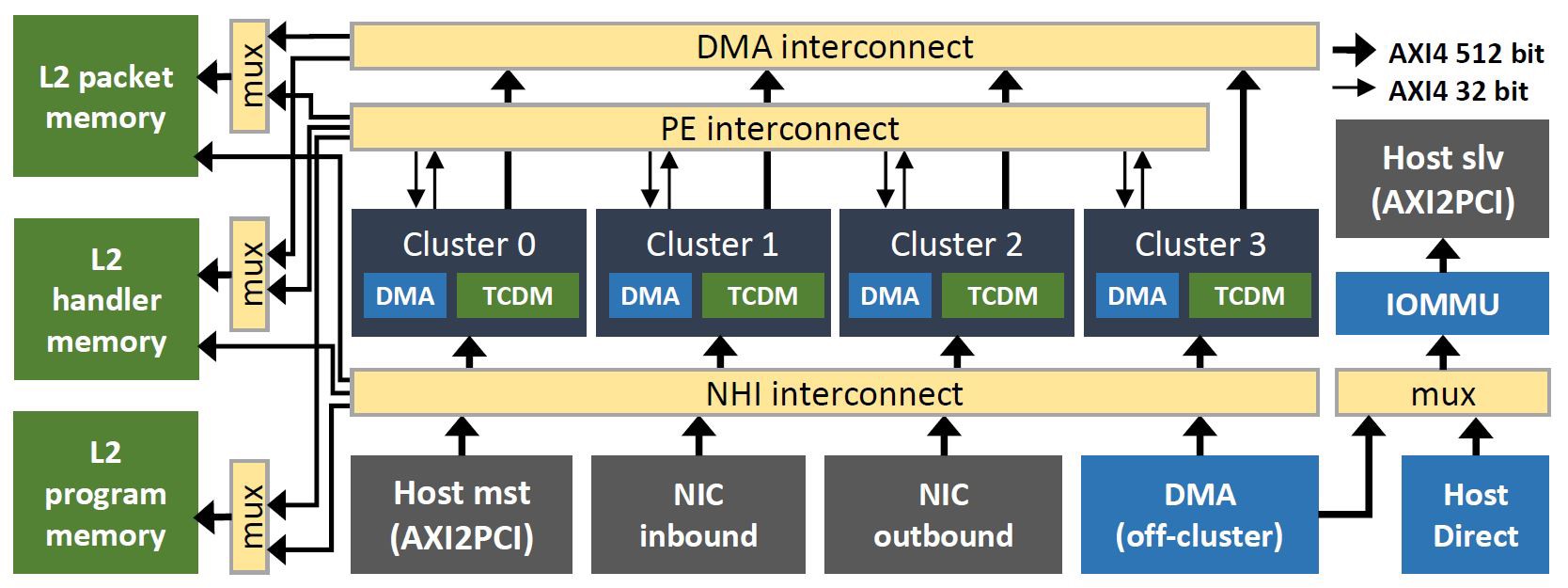
由于PsPIN是一个标准网卡附加的硬件,它对于网卡有一定要求。//待补充
评测
PsPIN的评测基于由SystemVerilog搭建的时钟精确模拟器进行。
延迟
在延迟方面,从PsPIN接收到HER到inbound engine接收到完成信号之间的时间间隔为26ns(64B)到40ns(1024B)。其中时间分布如下:
| 时延 | 过程 |
|---|---|
| 3ns | 处理请求到达CSCHED |
| 12ns~26ns | 数据包拷贝到L1 |
| 7ns | 准备handler |
| 1ns | handler通知HPU driver完成信号 |
| 1ns | HPU driver通知inbound engine完成信号 |
其中如果有HPU或者集群之间的仲裁还会引入6ns和2ns的时延。但是这些和上面提到的26ns和40ns不匹配,不清楚是如何计算的。并且这里忽略了对数据进行处理引入的时延。
吞吐量
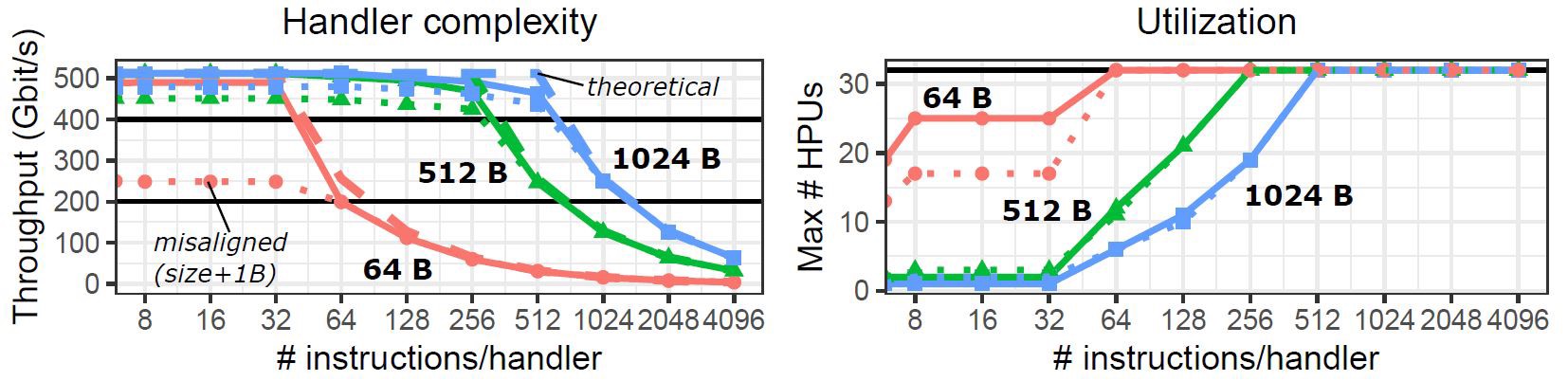
inbound吞吐量测试表明对于64字节数据输入,处理单元有32条指令的时间裕度,对于1024字节数据,有大约512条指令的时间裕度。
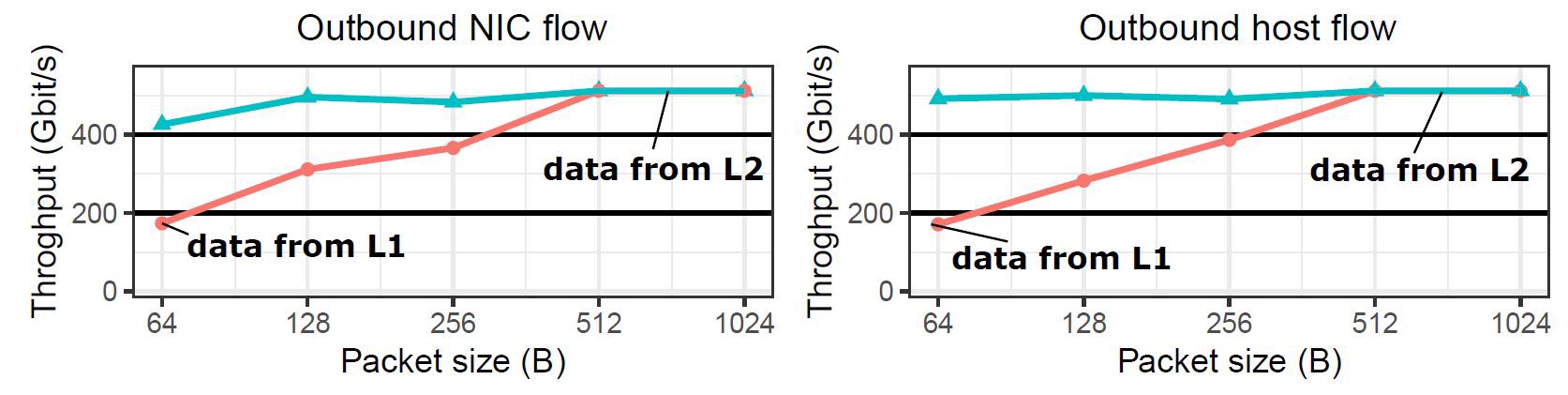
对于输出吞吐量,文章给的解释是由于L1的字长是32位,对于小包会频繁遇到bank conflict,导致吞吐量降低,随着数据包增大,时间预算足够L1处理bank conflict,因此吞吐量增加。
实际应用
本文将PsPIN和另外两个x86和ARM的处理器做了对比,在其上运行了多种应用,包括数据聚合、数据削减、数据包过滤、键值对cache、scatter和统计。